Automatic tweet sentiment analysis is a surprisingly exciting solution to everything from high frequency stock trading (as with Planet Money’s ‘Bot of the US’) to live monitoring of service up-statuses (such as the brilliant DownDetector).
Given these examples, I decided to try my hand at hacking together a solution for determining average tweet sentiment for a given hashtag over time. This solution features two major components: Tweepy-based tweet fetching and TextBlob-based sentiment analysis.
Fetching Tweets
First things first, we need tweets. For this it’s best to interact with the Twitter api for which Tweepy is a great option for Python. But the api has limits, we can’t just pull down every tweet since forever, instead we periodically pull down the latest tweets with a particular search term in it. This works perfectly as we’re interested in tracking sentiment over time, so grabbing the latest few tweets every 30 minutes should work perfectly.
Note that access to the Twitter api also requires the appropriate access tokens and keys. Once you have a twitter account, head to the apps page, fill in your app’s info and save the keys. Also note that this means that the Github version of the script will not work out the box, as I haven’t included my api keys. If you wish to use it, you should add your own keys at the top of the script.
Once fetched, we can perform some basic data cleansing to ensure only decent quality tweets are passed on for sentiment analysis. In this case, I filter out retweets (to reduce duplicate analysis), remove non-English language tweets (as these will confuse sentiment analysis), attempt to remove spam (excluding tweets containing links etc.), and remove any tweets left over from the previous day. Components of tweets, such a usernames and hashtags, are also removed to prevent issues with sentiment analysis.
Sentiment Analysis
Now we get to the core natural language processing step. For this, we’ll take advantage of the well-established ‘TextBlob’ library. For each tweet passed to TextBlob, we receive a sentiment score (-1 to 1 bounded, 1 means positive) and a subjectivity score (0 to 1 bounded, 1 means subjective).
These scores stem from the average of each component word’s individual score. For example, ‘beautiful’ has a base sentiment of 1.0 (very positive) and a base subjectivity of 1.0 (very subjective), whilst ‘absence’ has a base sentiment of 0.0 (very neutral) and a base subjectivity of 0.0 (very objective). We may then wish to exclude particularly subjective or objective tweets.
TextBlob is a little quiet about the specifics of its process, so it was fortunate that I discovered a blog which dived a little deeper into it. As an overview, here are some of the simple rules involved:
- Component words produce both a sentiment score (including of ‘great’ will make the score more positive) and a subjectivity score (‘beautiful’ is very subjective).
- Modifiers, such as ‘very’ or ‘not’ will impact the following word positively or negatively.
- Unrecognised words don’t impact analysis. Linguistically, we’ll be unable to determine the impact of particularly unusual word or recently introduced slang.
Current Insights
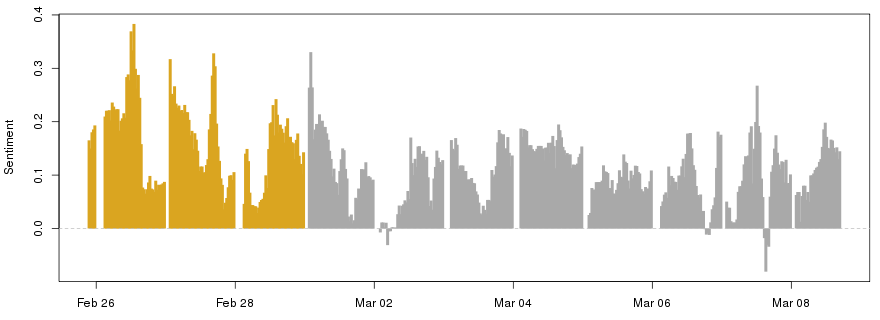
With the latest batch of tweet sentiments collected, we can store those scores over time and produce some analyses. In this example, I ran the script for the hashtag ‘#phdlife’ for a few days from February to March this year.
In general, we see that #phdlife is quite a positive place, with the average sentiment only rarely dipping into the negatives. Yet even in this short time frame we observe a couple of spikes up at lunchtime GMT on February 26th (to 0.334), and around half 4 GMT on the afternoon of February 27th (to 0.328). These scores appear to be boosted by the classic “That beautiful feeling when your paper gets accepted for publication! 😀😀😀” and its perfect sentiment score of 1.0, alongside an erroneously high score of 0.7 for “Mock viva day today! Anyone got any good advice?”, stemming from its use of the word ‘good’. This scoring oddidy is particularly clear when compared to the clearly positive “Ethics Committee approved my survey design without amendments - very excited” which scored only 0.488.
We also witness a more recent dip into negativity just after 3PM GMT on the 7th March (reaching -0.081). This is partially due to legitimately negative tweets, but also due to an erroneously low score given to “Woots~ journal published as a coauthor in Carbon, with an impact factor of about 6.3. not too bad for a start!”. This issue stems from ‘too’ not being recognised as an extension of ‘not’ towards ‘bad’. In fact, removing ‘too’ moves the tweet sentiment from -0.875 to the more accurate 0.438.
Next Steps
Given the need for real time daily data collection, this sort of analysis is pretty slow. I’m therefore going to keep these scripts running for now and may post an update if anything particularly interesting pops up. I may also fire up a couple more versions focused on other hashtags, perhaps even extending this project into a real time Twitter bot if the right niche should arise. For now, you can find the scripts on my Github.